
Introduction
Web scraping refers to the process of retrieving relevant data from websites. Looking for a simple piece of information on internet might be straight forward task, but if you want to build a large dataset using information available online, you will need to know web scraping. This article explains how to scrape websites in Python using Scrapy library, which is one of the most commonly used web scraping libraries in Python.
Goal
The goal of this article is to teach you how to scrape data from different websites via Python’s Scrapy library. We will scrape names of the teams in English Premier League football along with their stadium names. Therefore, let’s start without any further ado. Readers are expected to have familiarity with basic Python and object oriented programming.
Scrapy Installation
To install Scrapy using the pip installer, you need to execute the following command on your terminal:
$ pip install Scrapy
Else, if you have Anaconda distribution of Python, you can install Scrapy with the following script:
$ conda install -c conda-forge scrapy
Data to be Scraped
As I said earlier, we will be scraping the names of the clubs in English Premier League Football along with their home stadium names. The list of the teams is available at this link:
https://en.wikipedia.org/wiki/List_of_Premier_League_clubs
If you click the above click you should see a table containing names of various teams that play or have previously played in English Premier League Football. Here is a screenshot of the first 10 teams in the table:
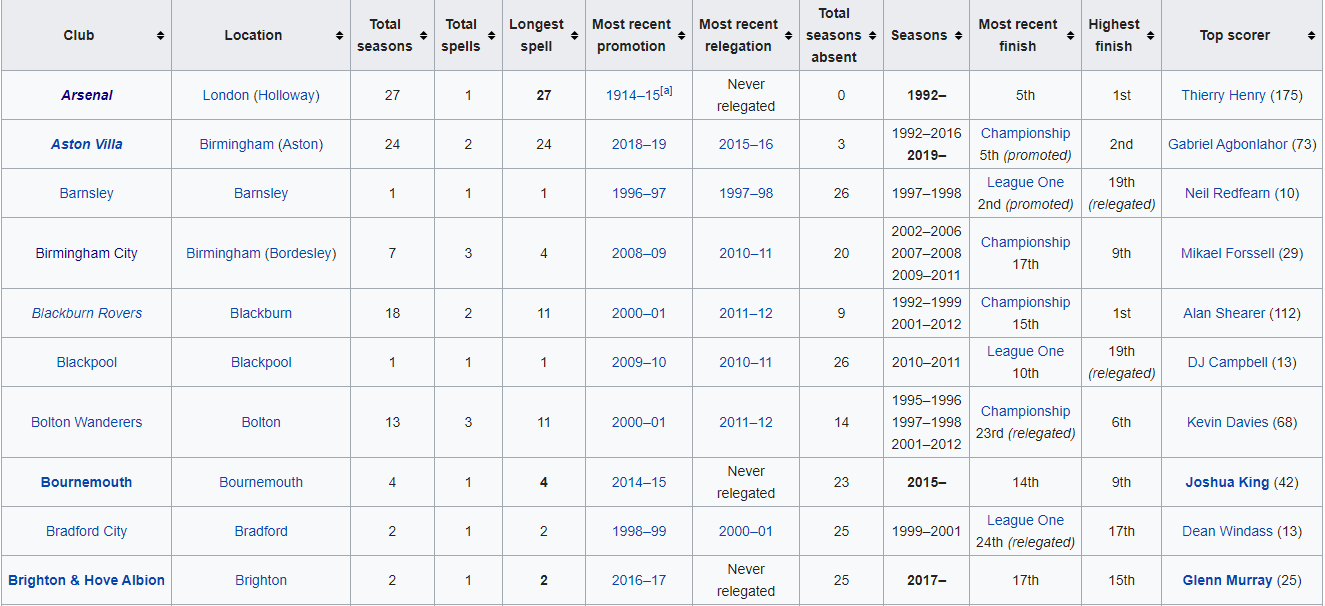
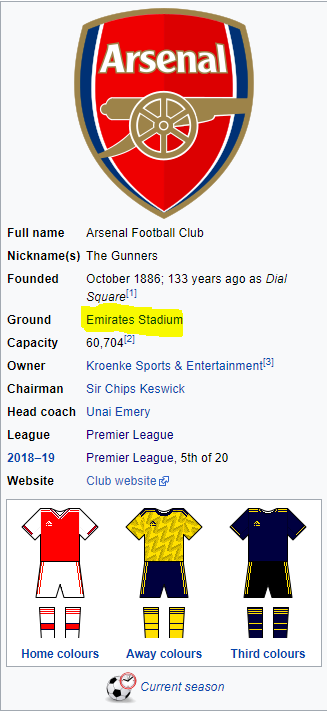
You can see that the stadium names are not mentioned in the table. To find out stadium names, click on the name of any team. The dedicated Wikipedia page for the team will open and you will be able to see the ground names in a side box on the right of the page. For instance, if you click Arsenal, you will be redirected to Arsenal’s dedicate Wikipedia page where you can see the ground name as shown in the following screenshot:
Scraping Information with scrapy
Now we know everything that we need to scrape. Let’s see how we can use Scrapy library to scrape the information that we need.
Creating a New Scrapy Project
To scrape websites with Scrapy, the first step is to create a Scrapy Project. The following command will create a new Scrapy project named pl_teams in your specified directory:
$ scrapy startproject pl_teams
Now if you navigate to the project directory, you should see the following directory structure:
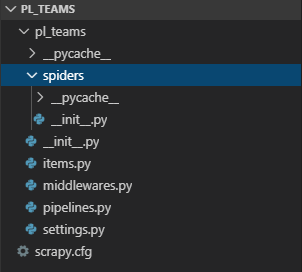
You can see that inside the pl_teams folder, there is sub-folder with the same name pl_teams. Inside the sub-folder there is a folder called spiders. Spiders in web-scraping refer to a piece of code that actually defines the scraping logic.
Creating spiders
Once a Scrapy project has been created, the next step is to create the spider that will crawl the Wikipedia website that contains list of Premier League teams. The following script creates a spider named pl_spider. Remember, the following command should be executed at the same directory level as the spiders folder.
$ scrapy genspider pl_spider en.wikipedia.org/wiki/List_of_Premier_League_clubs
In the script above, we use the scrapy genspider command to create a spider named pl_spider, which crawls the website en.wikipedia.org/wiki/List_of_Premier_League_clubs.
Now if you look at the directory structure, you should see the file pl_spider.py inside the spiders folder.
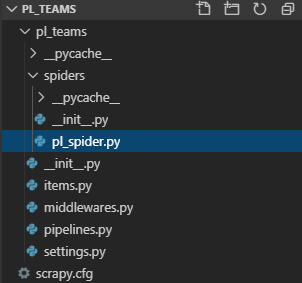
Scraping Team names
As a first step, you will see how to scrape team names. Open the pl_spiders.py file and make the following changes in the file:
# -*- coding: utf-8 -*-
import scrapyclass PlSpiderSpider(scrapy.Spider):
name = ‘pl_spider’
allowed_domains = [‘en.wikipedia.org’]
start_urls = [‘https://en.wikipedia.org/wiki/List_of_Premier_League_clubs’]def parse(self, response):
pass
Here the allowed_domains list contains the list of domains that will be searched for the data that we want to scrape. The start_urls list contains list of URLs, that will be searched for the data.
The scraping logic should be defined inside the parse() method since the parse() method is executed whenever a spider is run.
Web pages contain information inside HTML tags. Therefore, we have to search required data within the HTML tags. There are two ways to search data in an HTML document. You can either use CSS Selectors or you can use XPath Selectors. In this article we will use the XPath selectors to search data within the HTML tags. The explanation of the XPath selectors is beyond the scope of this article. I will just explain how the XPath selectors can be used to scrape team names from the Wikipedia page. Look at the following script:
# -*- coding: utf-8 -*-
import scrapyclass PlSpiderSpider(scrapy.Spider):
name = ‘pl_spider’
allowed_domains = [‘en.wikipedia.org’]
start_urls = [‘https://en.wikipedia.org/wiki/List_of_Premier_League_clubs’]def parse(self, response):
clubs = response.xpath(“/descendant::table[1]/tbody/tr/td[1]//a[not(ancestor::sup)]”)
for club in clubs:
name = club.xpath(“.//text()”).get()
link = club.xpath(“.//@href”).get()yield{
‘name’:name,
‘path’:link
}
The above script scrapes the names of the Premier League Clubs and the links to the Wikipedia pages of the corresponding Premier League clubs.
The XPath query used to search the names and links of the premier league teams is as follows:
/descendant::table[1]/tbody/tr/td[1]//a[not(ancestor::sup)]
The above XPath query tells the spider to search the first table on the webpage and then crawl inside the tbody/tr/ tags and the look for the first td tag. Inside the first td tag of each row of the table, retrieve the anchor tag a except those anchor tags that are inside a sup tag. You can verify this path using the inspect element property of your browser.
This XPath query is passed inside the xpath() method of the response object which returns all the links. Next, we iterate through all the links and store the link text in name variable and the value in the href attribute of the link is assigned to the link variable. Scrapy spider must return a dictionary. Therefore a dictionary is created that contains name and link variables. Finally, the dictionary is returned via the yield keyword.
Now to run the above pl_spider spider, run the following command at the terminal:
$ scrapy crawl pl_spider -o pl_teams.csv
The above script will scrape the names and links of the premier league clubs and will store them in pl_teams.csv file in the pl_teams subfolder. If you open the CSV file, you should see the team names and their corresponding Wikipedia page links.
Scraping Stadium names
We have successfully scraped the team names. Now is the time to scrape stadium/ground names for each team.
To do so, we need to make a couple of changes in the pl_spiders.py class.
Firstly, instead of returning a dictionary via yield keyword, we need to call the response.follow() method. We need to pass the link of the club’s Wikipedia page to the url attribute of the response.follow() method. Next, in the callback attribute, we need to pass the function name that will be called when the response.follow() method executes. Finally, we need to a pass a dictionary of values in the meta parameter. Look at the changes that we need in the parse() method:
class PlSpiderSpider(scrapy.Spider):
name = ‘pl_spider’
allowed_domains = [‘en.wikipedia.org’]
start_urls = [‘https://en.wikipedia.org/wiki/List_of_Premier_League_clubs’]def parse(self, response):
clubs = response.xpath(“/descendant::table[1]/tbody/tr/td[1]//a[not(ancestor::sup)]”)
for club in clubs:
name = club.xpath(“.//text()”).get()
link = club.xpath(“.//@href”).get()yield response.follow(url=link, callback = self.parse_club, meta = {‘name’:name})
When the response.follow() method executes in the above script, the Wikipedia page link of the team and the team name is passed to the parse_club() method.
Let’s now see how the parse_club() method will look like:
def parse_club(self, response):
club_name = response.request.meta[‘name’]
stadium_info = response.xpath(“//th[text()=’Ground’]/following-sibling::td[1]/a[1]”)
stadium_name = stadium_info.xpath(“.//text()”).get()
yield {
‘club_name’: club_name,
‘stadium_name’: stadium_name
}
The values passed in the response.follow() method inside the parse() method are received by the parse_club() method. The url value is stored in the response object. Similarly, the name of the club is stored in the club_name variable. Next, an XPath query is used to retrieve all the stadium names and the result is stored in the stadium_info variable. The XPath query simply looks for the th tag whose text is Ground and then simply returns the anchor tag a which is inside the first instance of the td tag that follows the th tag.
Next, from the HTML markup of the scraped anchor tag, text is filtered and stored in the stadium_name variable. Finally, the values for the club_name and stadium_name variables are returned via the yield keyword.
Again, execute the following script to crawl the pl_spiders spider.
$ scrapy crawl pl_spider -o club_stadiums.csv
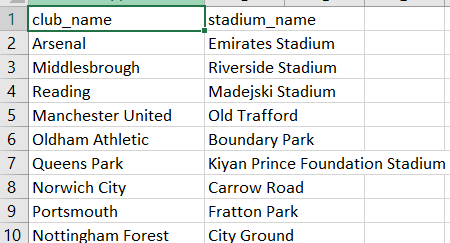
Once you execute the above command, you should see a file named club_stadium.csv inside the pl_teams folder. If you open the file, you should see the team names along with their stadium names as shown below:
Conclusion
Web scraping can be very useful specially when you want to create huge data sets using the information available online. This article explains how to scrape websites using Python’s Scrapy library. The article shows an example of how you can scrape names of English Premier League clubs along with their home ground names.
”




